craigrussell
Technical blog from Craig Russell.
Should Repositories expose suspend functions?
When using coroutines in Android, you have to choose which functions will be marked as suspend. How and where you do this across your app is an architectural decision. This post discusses whether the Repository layer should expose suspend functions or not.
What is a Repository in this context?
A common layer in Android app architectures is a Repository layer. Exactly where it sits in your layers, and who its immediate neighbours are, might vary depending on your architecture flavour, but a Repository will typically sit somewhere below your view layer and above your data source layer. Its purpose, in part, is to let you decouple and encapsulate the exact mechanism of data storage from the layers above.
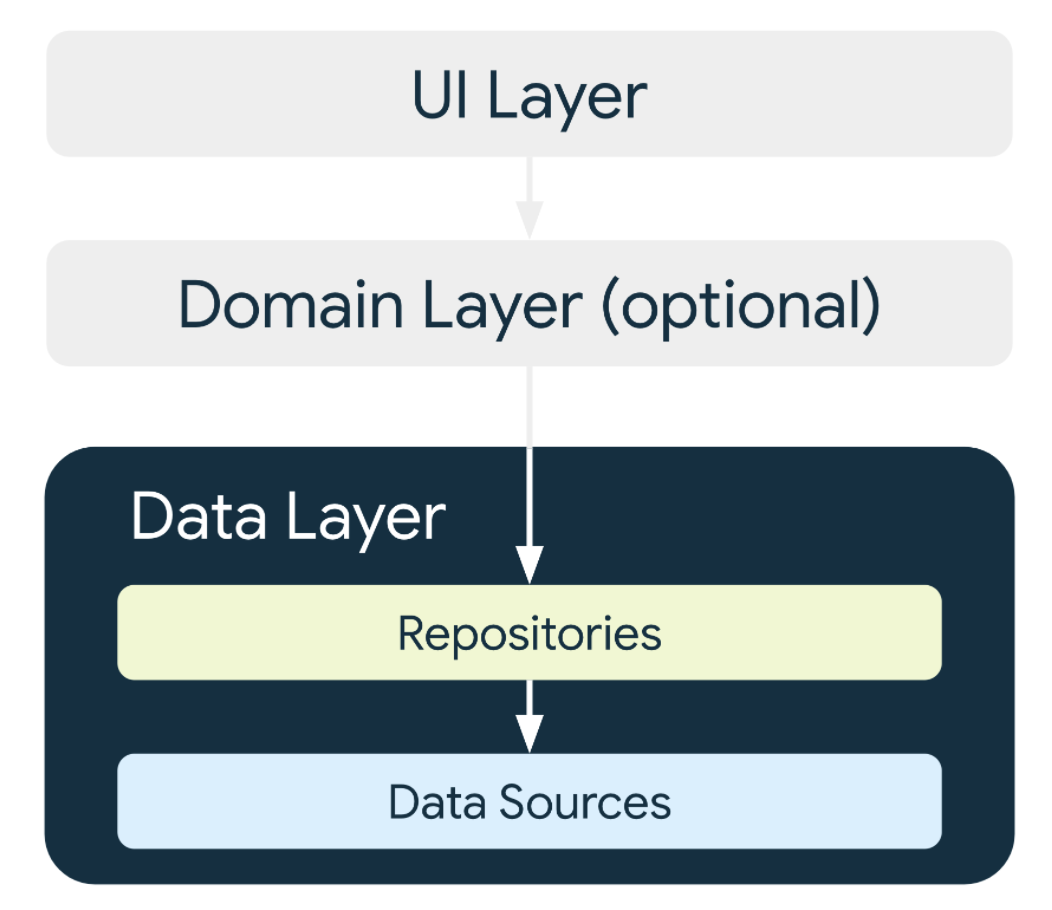
Your Activities, Fragments, ViewModels et al. should not need to know precisely how you are storing data; that is an implementation detail that can be forgotten about at those higher view layers. The view layer can talk to a Repository to get and save data, all without the need to understand Room DB, DataStore, SharedPreferences, Files etc…
This post focuses on suspend functions, but more generally covers whether to have coroutine-specific features exposed by your Repository APIs, and so extends to whether to return Flow or not.
Data access needs to consider threading
In an ideal world, reading and writing data would be so quick to perform that we could do it from the main thread, but that’s not the case. Often, data access involves making network calls and even when all operations are done on local storage only, you still can’t be guaranteed they’ll happen quickly enough to be allowable on the main thread (data access speeds are so variable on Android, IO disk resource contention might slow it down etc…).
Whether making remote network calls or reading/writing from local storage, we need to assume that it can take a few moments to complete and avoid using the main thread.
Who chooses the thread?
If we consider the scenario where an Activity talks to a ViewModel which talks to a Repository which talks to a Room DAO, who is responsible for ensuring the data access happens off of the main thread?
Specifically at the Repository level, should the Repository internally handle the threading or should that be left up to the caller of the Repository to get it right?
Let’s say we have this Repository, which uses a Room DAO to persist data.
class BookmarksRepository(private val bookmarksDao: BookmarksDao) {
fun insert(bookmark: Bookmark) {
bookmarksDao.insert(bookmark)
}
}
The insert function in this example is not marked as suspend. Should it be?
Arguments against exposing suspend functions
- ➖ Forces callers to use coroutines
- ➖ Calling code should own threading decisions
Forces callers to use coroutines
An argument against exposing suspend functions from the Repository is that it forces all callers to be coroutine-aware.
- The only way to call a
suspendfunction is from inside a coroutine - Therefore, you create demands on all calling code that it also handle coroutines to some degree
- This dependency on coroutines leaks and propagates throughout your codebase
Calling code should own threading decisions
Another argument is that the calling code can (and should) make decisions about the threading
- Each caller might have particular needs, and can make the decision on threading based on its own known needs
- The Repository functions can be thread-agnostic and solely execute the logic on the thread it was invoked from, without trying to also handle threading
Arguments for exposing suspend functions
- ➕ The best decisions on threading requires knowledge of internal workings
- ➕ Forces correctness on calling code
- ➕ You are forced to think
The best decisions on threading requires knowledge of internal workings
The caller can’t always make the best threading decisions without knowing the internal workings of the Repository (which we want to avoid).
For example, it might seem reasonable for the calling code to always ensure it executes the Repository function on a background thread (e.g, Dispatchers.IO), but that might create inefficiency. If using Room for example, it is wasteful to switch dispatcher at a higher level because Room handles this internally.
your code should not use
withContext(Dispatchers.IO)to call suspending room queries. It will complicate the code and make your queries run slower. (Source)
In other cases, you might need to perform some complex operations after retrieving the data from the data source, but before returning it from the Repository.
- Ideally, you’d perform the data retrieval on a dispatcher made for IO (e.g.,
Dispatchers.IO) and then jump to a dispatcher made for more CPU-intensive operations (e.g.,Dispatchers.Default). - If you are relying on the caller to dictate the threading model, this is very hard for a caller to get right without knowing far too much about the inner workings of the Repository.
Forces correctness on calling code
Another argument for exposing suspend functions is that it’s hard for callers to get threading right by themselves and the use of suspend can force correctness upon them.
Use of suspend alone could still allow a caller to call it from a coroutine executing on the main thread (e.g., Dispatchers.Main). So how does the suspend function offer a way to reduce errors here?
- Internally, inside the
suspendfunction in the Repository, you can ensure the heavier operations happen on the correct dispatcher. - You can use
withContext()and provideDispatchers.IO,Dispatchers.Defaultas well as your own custom dispatchers; ensuring each is used at the correct times - You can make all your Repository functions main-safe; safe to call from the main thread without the caller needing to know precisely what’s happening internally.*
- The calling code can’t get it wrong
*Main-safety
The ability to call Repository functions in a main-safe way isn’t enforced by the compiler; you as developer of the Repository still have to do that. It’s trivial to do with withContext, but you still have to do it. But it’s easier to get that right once when writing the Repository function than having to get it right from every caller that calls it in the future.
Interestingly, Google go so far as to state that all suspend functions should be main-safe, but that’s a different debate for a different day. 😅
Suspend functions should be main-safe, meaning they’re safe to call from the main thread. If a class is doing long-running blocking operations in a coroutine, it’s in charge of moving the execution off the main thread using withContext. This applies to all classes in your app, regardless of the part of the architecture the class is in.
You are made to think
An immediate effect of trying to call a suspend function is that you get a big hint the function might not complete quickly, and that this requires you to think.
- If calling a function not marked with
suspend, without anything to enforce otherwise, it’s easy to end up assuming a call will be fast and making it from the UI thread - Don’t make me think… unless I’m about to use a footgun.
Don’t keep me in suspense; what’s the recommendation?
While I get the sentiments behind some counter-arguments, my recommendation is to expose suspend functions from the Repository layer.
It is also a recommended practice by Google, in their Coroutines Best Practices guide: https://developer.android.com/kotlin/coroutines/coroutines-best-practices